학교에서 진행한 데이콘 스쿨에서 2022년 6월 29일부터 2022년 8월 8일까지의 교육 중 세 번째 대회의 일지를 쓰겠다.
세 번째 대회는 버스 운행 시간 예측 대회였다.
next_arrive_time : 다음 정류장에 도착할 때까지 걸린 시간 (단위:초)를 예측하는 대회이다.
이번 대회는 인사이트를 도출하기에 어려운 대회로 느껴졌다.
많은 인사이트를 만들어내려고 노력했지만 다 실패를 했다..
실패한 나만의 인사이트들을 적어보겠다.
나만의 인사이트
가설1: 요일에 따른 버스 운행 시간이 다르지 않을까?
가설 1은 낮은 상관관계와 낮은 안 좋은 RMSE로 실패
가설 2: 그래도 주말과 평일의 차이가 있지 않을까?
bar형태로 그래프를 그려본 결과, 주말과 평일의 버스 도착시간 평균은 거의 비슷했다. - 실패
가설 3: 출근 시간과 출근 시간 외의 운행 시간 차이가 있지 않을까?

이 역시도 별 차이가 없어 사용하지 않았다.
가설 4: now_arrive_time에서 24시가 0으로 표시되어있는데 24로 표시해주면 더 예측을 높이지 않을까?(오후 11시는 23으로 표시되어있다)
이 역시도 RMSE가 더 좋지 않았다. - 실패
가설 5: 현재 경도와 다음 경도의 차이가 클수록 next_arrive_time의 차이가 크지 않을까?
음이나 양의 상관관계를 보이지 않았고, next_arrive_time와의 상관관계가 좋지 않았다. - 실패
Feature Engineering
거리를 비닝해주었다. 10개 정도로 구간을 나누어 비닝을 해주어 새로운 열로 추가해주었지만 더 안 좋은 RMSE값이 도출됐다. - 실패
이번엔 거리에 로그를 씌어주어 정규화에 더 가까운 모양으로 만들어주었다.

원래 거리 그래프이고 여기에 로그를 씌어주면
sns.distplot(np.log1p(train['distance']), fit=stats.norm)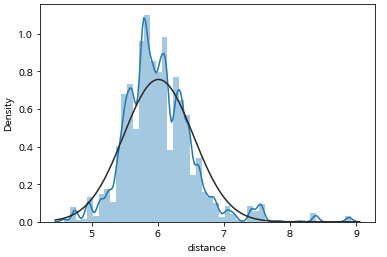
그래프가 정규분포와 가까워지기에 예측했을 때 더 좋은 값이 나올 것이라 추측했으나, 변화가 없었다.
많은 시간을 들여 인사이트를 만들어냈지만 다 실패했다. 역시 인사이트를 만드는 것은 어려운 일이다.
그래도 실패하고 실패하며 어떤 아이디어를 생각해내고 어떤 식으로 진행해볼지에 대한 창의성을 기를 수 있었다.
또 계속하다 보니 데이터에 대한 이해도가 높아졌다.
교육시간에 스케일링하는 법을 배웠다.과도하게 큰 값을 가지는 변수들을 스케일링해주면 보다 작은 값으로 변하여 변수들 간의 값을 비교하기에 더 좋다.
스케일링 중 하나인
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()을 보면 0~1 사이의 값을 갖도록 스케일링을 해준다.
배운 이 스케일링을 가지고 거리 변수에 적용을 해주었지만 이것 역시 변화가 없었다.
이렇게까지 변화가 없다니.. 뭔가 어디서부터 잘못된 건 아닐까라는 의심도 들었지만 잘못된 부분을 찾기는 어려웠고 다시 실행해도 계속 같은 값이 나와 아쉬웠다.
저번 교육시간에 다른 변수를 스케일링할 때는 예측력을 더 높여줬는데, 아무거나 스케일링을 한다고 다 예측력이 높아지는 것은 아니라는 점을 깨달았다.
아 그리고 RMSE와 같은 예측력을 보기 위해서는 validation 셋을 구축하여 보면 알 수 있다. train을 이용하여 validation셋을 구축하여 예측력을 보고 예측력이 좋으면 test에 적용해주는 식으로 나아갔다.
from sklearn.model_selection import train_test_split
X_train, X_valid, y_train, y_valid = train_test_split(X,y, test_size=0.1, shuffle=False)
이번 교육시간에 새로 배운 모델은 두 가지였다.
xgboost 모델과 catboost 모델!
xgboost 모델은 많은 대회에서 쓰인다고 한다. 나도 자주 써야겠다ㅎㅎ
catboost 모델은 원핫인코딩과 같은 역할을 해준다. 즉 범주형의 피쳐 처리가 가능하다!
xgboost 모델
import xgboost as xgb
model = xgb.XGBRegressor(objective='reg:squarederror', n_estimators = 3000, tree_method='gpu_hist')
model.fit(X_train,y_train, eval_set=[(X_valid,y_valid)],
eval_metric = 'rmse',
early_stopping_rounds=10,
verbose=5
)
y_pred = model.predict(X_valid)catboost 모델
cat_features = [0,1,4] #범주형 피쳐 처리를 할 인덱스
model = CatBoostRegressor(n_estimators = 6000,task_type='GPU')
model.fit(X_train, y_train,
eval_set=(X_valid,y_valid),
cat_features=cat_features,
use_best_model=True,
verbose=True
)
y_pred = model.predict(X_valid)
이번 대회는 열심히 예측력을 높이기 위해 노력했지만, 더 좋은 변수를 찾거나 예측력을 높이는 나만의 방법을 결국 찾지 못했다. 그래도 교육에서 배운 게 많아 유익한 시간이었다. 변수를 만드는데 실패는 했지만, 이 실패 경험 또한 나중에는 값진 도움이 될 것이다. 그리고 평소에 알고 싶었던 모델 두 개를 알게 되어 좋았다. 앞으로 자주 사용할 것이다.
