개발일지2
학교에서 진행한 데이콘 스쿨에서 2022년 6월 29일부터 2022년 8월 8일까지의 교육 중 두 번째 대회의 일지를 쓰겠다.
두 번째 대회는 따릉이 대여량 예측 대회였다.
대여량 예측 대회를 하기 전 교육을 해주셨는데 교육시간에 배운 split은 년, 월, 일을 나눌 때 도움이 많이 됐다.
train['date_time'][0].split('-')
-> ['2018', '04', '01']
train['date_time'][0].split('-')[1]
-> '0.4'
그리고 lambda를 사용하면 함수를 간단하게 표현해줄 수 있다.
train.apply(lambda x : x*2)이런 식으로 해주면 def를 사용한 함수를 사용하지 않고도 한 줄로 나타내 줄 수 있다.
x는 매개변수이고 x*2는 적용해줄 함수 식이라고 한다.
나는 최대한 새로운 열 만들어내기 위해 가설을 생각해 냈다.
'하늘이 맑고 강수 확률이 낮으면 따릉이 대여량은 증가할 것이다.'라는 가설을 세웠다.
그래서 피쳐인 하늘 상태와 강수 확률을 곱해 파생변수를 만들어냈다.
하늘 상태는 (맑음(1), 구름 조금(2), 구름 많음(3), 흐림(4))이었기 때문에 강수확률과 곱했을 때 그 값이 높을수록 따릉이 대여량은 감소할 것이라고 생각했다.
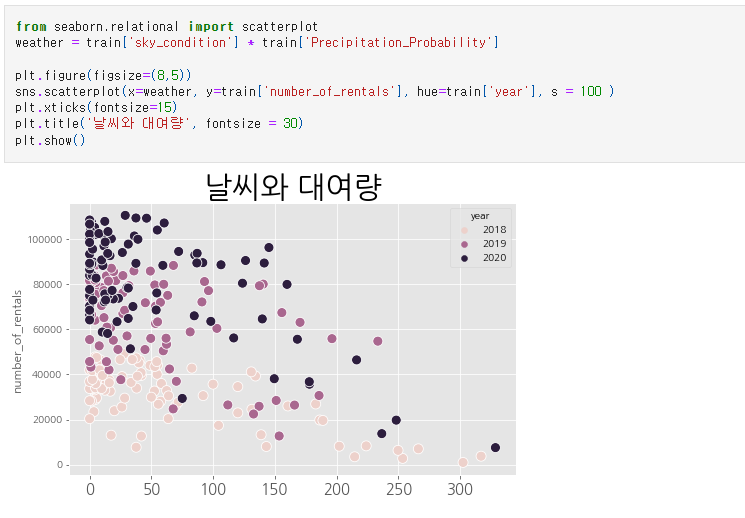
그 결과 반비례의 그림이 나왔고, 상관관계 역시 -0.45로 높이 나와 따릉이 대여량의 변화에 영향을 줄 것으로 판단되어 파생변수로 생성해줬다. 그랬더니 더 높은 예측력이 나왔다.
그리고 그리드서치(GridSearchCV)를 통해 RandomForestRegressor()의 최적의 하이퍼파라미터를 찾아내려고 노력했다. 처음에 최적의 하이퍼파라미터를 어떻게 찾아야 할지 고민하며 검색하던 중 그리드서치를 알게 되어 사용했다.
이 덕분에 하이퍼파라미터를 잘 만들어 줬더니 좋은 예측력이 나왔다.

이렇게 그리드서치와 새로운 파생변수를 만들어 예측력을 높였지만, 그와 반대로 많은 시도를 했지만 예측력을 높이지 못한 경우도 정말 많았다.
시도해본 것들 중에서는 RandomizedSearchCV을 이용해 하이퍼파라미터를 찾으려고 했지만, GridSearchCV보다 안 좋은 값이 나왔다. 또, differ이라는 파생변수를 만들었지만 예측력을 더 안 좋게 만들었다.
differ은 온도차가 클수록 대여량이 감소할 것이라는 가설에서부터 시작했다.

하지만 그림에서 보이듯 정확한 관계가 보이지 않았고, 대여량에 큰 영향을 주지 않아 보였다.
differ을 넣어 예측력을 보니 역시나 더 안 좋아져 이 파생변수는 제거시켜줬다.
이번 두 번째 대회를 통해 최적의 하이퍼파라미터를 찾는 것은 어려운 일이고 예측력을 높일 수 있는 파생변수를 찾는 일은 어렵다는 것을 알았다. 많은 시간을 할애했고 노력하여 이번 대회에서는 2등이라는 좋은 성적을 거둘 수 있었다.
다음 대회에서도 더 발전된 모습이 되길 바란다.